In February this year, the Cabinet Office Transparency Team started to tackle the problem of broken links on data.gov.uk. These are links to data files listed on data.gov.uk that give an error when you click to download them. The public body that hosts the data may have made an error when giving the data's location in the first place, or may have changed its location or it could be one of the dozens of bodies moving their whole sites onto gov.uk. The organisation may also have been dissolved or changed, as happened when the structure of the NHS was overhauled last year. In February, the number of broken links across the site sat at 9,348, representing around 14% of all data files on data.gov.uk.
The data.gov.uk developers began to look at batch fixes, updating links where they had been moved or making use of the National Archives central government website archive. In addition, tools to automatically check for the broken links have been developed. With the help of the Cabinet Office Transparency Team, organizations are working methodically through the lists of broken links and have so far made hundreds of corrections. This work has led to a significant reduction in broken links with around 4,175 or around 6% of files on data.gov.uk remaining broken. However, this figure is obviously still far too high.
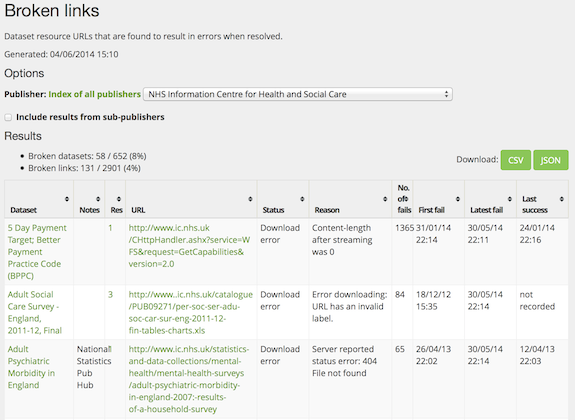
The 'broken link checker' is software that automatically tests data links in data.gov.uk. When a link is added to data.gov.uk, the link is tested then and thereafter on a weekly basis. The results are shown on a report that is assembled nightly and is publicly viewable here: http://data.gov.uk/data/report/broken-links. We also show the problems on the dataset itself - broken links are marked with a red exclamation mark. The broken link reports have been running for a year and have been refined over time. We have gradually exposed them to public bodies and now openly to everyone. We hope this will help get the broken links fixed, and set user expectations more realistically, before they click on the bad links.
The broken link checker and reports are developed in open source as extensions to CKAN. The majority of governments round the world are using CKAN for their open data catalogues, collaborating and benefiting from open source development. There has already been plenty of interest in these particular tools from outside of the UK Government. The code is here: https://github.com/datagovuk/ckanext-archiver https://github.com/datagovuk/ckanext-report.
1 comment
Comment by exstat posted on
I can't help thinking that part of this is self-inflicted through insisting that site move onto gov.uk, or are reduced in number. It matters not a jot to me where a file or feed is, as long as it is signpisted centrally from the appropriate place (data.gov.uk, the National Statistics website or wherever). Reducing numbers of sites seems to me a political obsession rather than one with any great benefits.
What does matter a jot to me is that the file or feed stays in the same place wih the same name. We should not forget that many users of government data are not seeking to data link or change the world with it but to do something modest but still of value. There are community websites springing up all over the place, some of which link to pages/files on the sites of lcoal authorities, transport authorities such as TfL, the NHS and so on. Some may even link to neighbourhood crime figures and the like.
The people running these sites in their spare time have not got the time to keep checking that links still work, nor should we expect them to. Wholesale moves and redesigns of websites are a pain. But an even bigger pain (because it is more frequent) is the failure of some data publishers to use consistent naming conventions. I have seen sites where successive generations of an output are called things like
miltonkeynes
milton-keynes
miltonkeynes-a4
mkeynes_and_bletchley
Then a new version is put up in advance (miltonkeynes_140606, say). Fine, that distinguishes it from the current one. But then it does not get renamed when it becomes current? Not necessarily. (There are situations where this is the right thing to do, because there is a commitment to maintain the older versions of documents as well, but tven then a consistent naming convention should be adhered to.)
So the poor website maintainer has great difficulty in providing a link to the page or document in question and the user ofthat website is going to be directed to an error page or (unknowingly) and obsolete version.
This "rant" may seem to be about trivialities compared to the big issues people like to discuss about linking, copyright, use of RDF, Big Data and so on, but they should not be dismissed. And. to go back to the beginning, some of the problems may have been exacerbated by the apparent imperative to reduce numbers of websites.