I'm Peter Jackson, the Head of Data at The Pensions Regulator (TPR). In this blog I’m going to tell you about how we have collaborated with the Better Use of Data Team at the Government Digital Service to use our data on pension schemes better by pioneering the use of Machine Learning at TPR.
The Pensions Regulator is the UK regulator of workplace pension schemes. We work to ensure that pension schemes are adequately funded and run in the best interests of retirement savers. We also make sure that that employers are meeting their new obligations to automatically enrol their staff into a pension scheme. We regulate around 40,000 occupational pension schemes varying from very large schemes with hundreds of thousands of members to very small schemes with just a few members. To help us do this, most of these pension schemes are required to report key information to us through a regular scheme return.
Using our data better
For some time we have been working on exploiting the data we hold to segment the schemes we regulate, depending on how likely we think that they are to comply with this return. We want to use this segmentation to personalise how we communicate with a varied range of pensions schemes.
So far we have only been able to look at historical behaviour, but we were keen to start making predictions about what pensions schemes will do in the future. To do this we collaborated with the Better Use of Data Team at GDS. Their data scientists and delivery manager spent several days with our policy, operational and data experts, learning about how we work, our business processes and our data, before making a proposal for a piece of work they thought could showcase the value of data science for TPR.
Machine Learning
After looking at our pensions scheme data, the GDS data scientists suggested building a Machine Learning model to predict future pension scheme behaviour; whether the scheme will make its return on time, be late, or not make a return at all. As we have data about pension schemes going back several years, labelled with whether they complied with the requirement to submit a scheme return we were able to build a supervised machine learning model, which learns from our existing data and can be used to make predictions about how a pension scheme will behave.
The data scientists explained that the first stage of a machine learning or predictive analytics project was Feature Engineering, creating new columns of data which help us extract more meaning. Sometimes feature engineering can take the form of summarising the data. For example how many times has a scheme contacted TPR in the last year? Of all the returns a scheme has made how many were submitted late? In other cases it can be computing new variables from the data, for example how long a scheme has been active for (computed from its registration date) or how long since it last contacted TPR.
There are a wide range of different machine learning algorithms that work in different ways. For this project the data scientists chose to do most of their work with Decision Trees.
Decision trees are one of the most widely used machine learning algorithms, and are used everywhere from Agriculture, Finance and Medical Devices to targeting Tax Investigations, like this example from HMRC.
They are very flexible and can be used to predict binary (Yes or No) outcomes; like whether a pension scheme will have sent its return in by the due date or not. More complex outcomes can also be modelled, such as whether a pension scheme will send its return on time, be late, or never make a return.
When we are trying to predict if a pension scheme will send its return in by the due date, we start by splitting our schemes into two groups, one with as many on time returns as possible and one with as many late returns as possible. We use statistical algorithms to find the data that lets us split our schemes into two groups which are as different as possible. For example, if we make a split based on previous contact, i.e. group A that has never contacted us before, and group B that has been in touch, then it is possible that we might find a lot more late returns in group A.
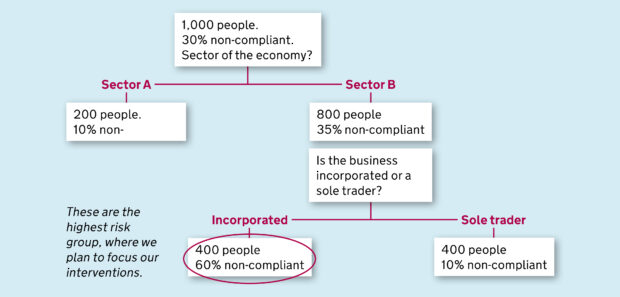
On its own this isn’t very useful, but if we keep repeating the process, splitting each group up again and again using different data each time, we end up splitting our pension schemes into lots of different groups each with a different likelihood of being late. There are some great interactive explanations of how decision trees work which are really worth exploring, like this example from R2D3 which show a decision tree used to predict house prices.
Decision trees were ideal for this project; because they cope well with a mixture of numerical and categorical data, and need little data preparation so they can be used to produce models very quickly. They also produce transparent and intuitive models, which meant they could easily be presented to a range of stakeholders in TPR, some of whom are new to data and data science, and easily implemented within our existing corporate IT infrastructure.
The final model uses our data to split pension schemes into around 30 different groups, each which will behave differently, providing a ready made segmentation. For example, there are groups where most pension schemes are expected to make a return on time, and other groups where a large proportion of schemes are expected to be late or never make a return. This is great as we can tailor our communication strategy differently for each group; light touch when we expect schemes to make returns on time, firmer where we expect a scheme to be more problematic. In addition it can lead to further investigation of the data associated with that scheme. Are the contact details for the scheme correct? Is the company or trustee associated with that scheme no longer in place?
Working with GDS
Working with the GDS team was a great experience. They were passionate about data science and how we could use it to improve TPR, and they had the skills to explain complicated ideas in a simple and engaging manner to all sorts of people across the organisation.
GDS data science expertise delivered an innovative data product for us, which has given us a great platform from which to continue to make TPR a more data driven organisation. We have also been able to work with GDS to build in-house data science capability, with some of our existing analysts participating in the Data Science Accelerator Programme.
Approaching our existing data in a different way also helped us focus on data quality issues like missing and dirty data. By cleaning up these issues we hope to continue to find innovative ways of improving our engagement and enforcement.
GDS and TPR are just one small part of a growing government data science community. If you want to find out more please join the Data Science Community of Interest mailing list.
Peter Jackson is the Head of Data at The Pensions Regulator.
Recent Comments