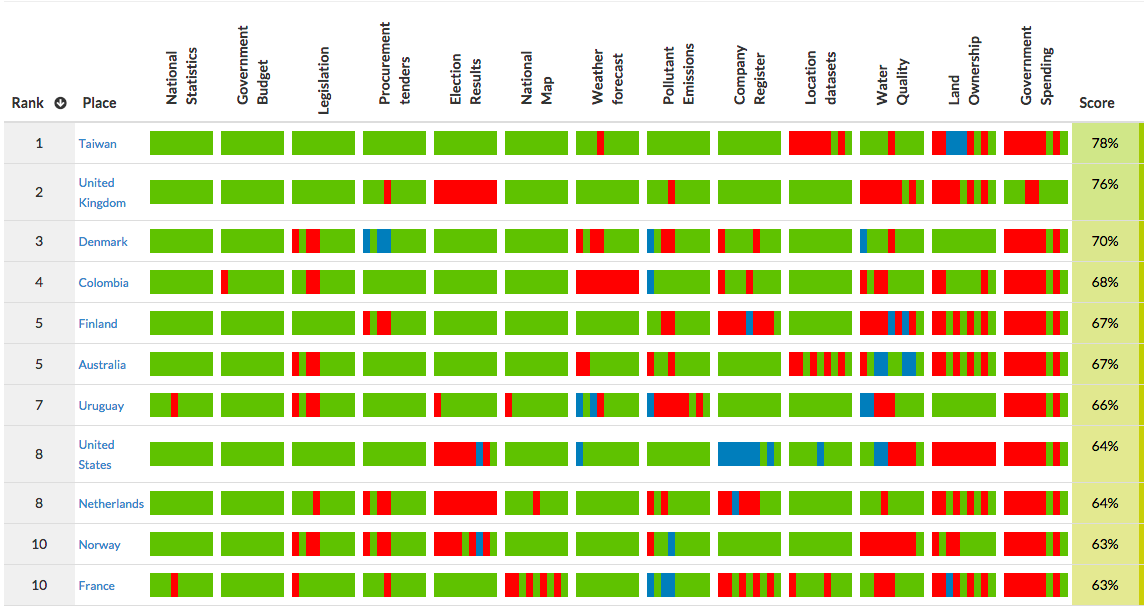
Last week Open Knowledge published the third edition of their annual Global Open Data Index. This year Taiwan topped the table of 122 countries, with the UK finishing second - pipped to the top spot after two years as the best performers globally, but still - we think - a highly creditable finish.
While extending our warmest congratulations to Taiwan, we’re obviously a little disappointed to have lost our claim to being the Undisputed Open Data Champions of the World (we await the result of the World Wide Web Foundation’s Open Data Barometer with great interest…); but then we have always known that in this incredibly fast-moving area - one in which we’re all more often than not in unchartered territory - the friendly international competition is intense. In fact, it’s an essential part of what makes Open Data such an exciting agenda to work on.
Such is the rapid evolution of the Open Data agenda, it’s not just the publishers of data that are breaking new ground - so too are the compilers of league tables. The Global Open Data Index is itself evolving. Open Knowledge face the huge challenge of creating an index that’s relevant across all 122 countries they review - and identifying those datasets that can really make a difference to the accountability of governments, their economies, and quality of public services if opened up.
Inevitably, that means that some criteria are an awkward fit in different national contexts - for example, on elections data the UK went from first in the world last year to 87th this year, scoring zero, despite the Electoral Commission providing a comprehensive set of open data. This year countries were only awarded points if they published data on national elections at the level of individual polling stations. This matters in many national contexts because granular data is important in preventing fraud - but in our system, we simply don’t count votes at that level. The 1983 Representation of the People Act explicitly requires votes from polling stations to be pooled in the interests of protecting the identity of voters in the event that a candidate receives a very small number of votes. This change cost us the top spot and if the measure is kept next year we’d need to change the laws governing our electoral system to make progress.
Similarly, we were expecting our colleagues in France to be biting at our heels, and we were surprised they were only recorded as 10th in these measures. But despite inevitable quibbles about measurement these type of benchmarks are something we and the wider UK government take seriously; they are one of the ways we can assess how well we are doing. Indeed, there was a longer article on this over at Civil Service Quarterly by Cabinet Office colleagues a few months ago.
For instance, the Index does highlight things that we can do rather more quickly. There are a couple of measures - for example on government spending - where we have lost points versus previous years. This is not acceptable, and it’s an important spur to action on our part to keep on top of timely, accessible publication of data like this. And there are other criteria where the index highlights areas of opportunity - land ownership, water quality and pollutant emissions, for example - where we can use these results in conversations with data owners to explore ways we can open up further.
So we’re grateful to Open Knowledge - and the formidable team of volunteers that help create the Index each year - for providing us with a means for checking our progress and highlighting opportunities to develop further. Having tasted success at the very top of the table in previous years, we’re all the more determined to do so again; and as our new Government Data Programme develops momentum - not just opening datasets but tackling the core data infrastructure that is necessary to drive data use and quality - we’re confident we have a strong foundation to accelerate our progress. Roll on 2016.
Recent Comments