Data.gov.uk exists for two reasons: to facilitate the publication of good quality open data by government organisations and to make it easy for users to find it.
Different users, different needs
As we’ve said previously, data.gov.uk has 2 groups of users: government publishers and open data users. The tasks they need to do on our site are different, and so are their needs.
After our discovery revealed the jobs that users and publishers want to get done, we decided to focus on two strands of work:
- making it easier for government organisations to publish good quality open data
- making it easier for users to find government’s open data
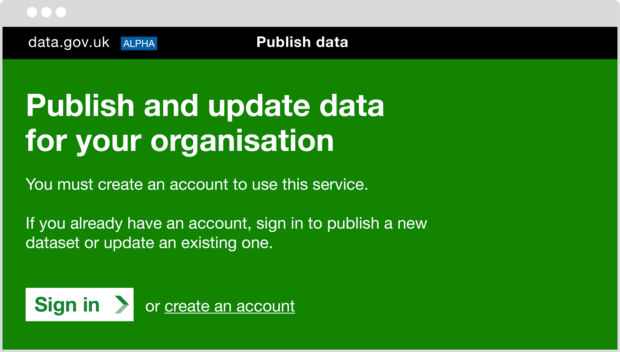
This is the new-look ‘start page’ for the alpha Publish Data service:
Improving the publishing flow
The publishing process is not the main focus of the teams responsible for getting government’s open data out there. Publishing data is something they want to do quickly and simply.
In the alpha version of the Publish Data service we’ve reduced the complexity of the publishing and updating process by removing unnecessary steps, using plain English and adding clear guidance where necessary. We’re also improving the date range and location fields for datasets.
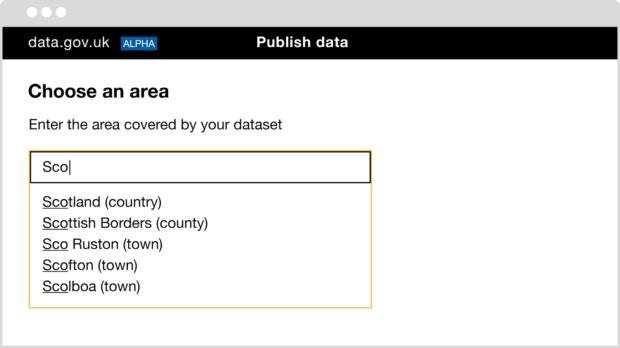
Understanding how end users make use of data and what they need to know about datasets has helped us determine the type of information we’re asking publishers to provide.
We’ve made these decisions after extensive research with end users and we’ll blog about this soon.
Getting more people involved in publishing
The teams tasked with publishing open data on behalf of their organisations also gave us some valuable feedback on how they’d like to see the publishing process change to better meet their needs.
I want others to start to take ownership of their data and a major obstacle is the use of the tools. This makes it easier for them to publish their own data
Over a number of workshops, they showed us their internal data management processes and helped us understand that if the data could be published by those who generate it, then data quality would improve. At present this is difficult to do because the publishing process isn’t flexible enough to support this degree of collaboration. Over the next few iterations we’ll be working on changing that.
Improving the quality of the data
Teams also wanted more support to improve the quality of their data, fix broken links and most importantly make timely updates. We took note and we're introducing personalised reminders.
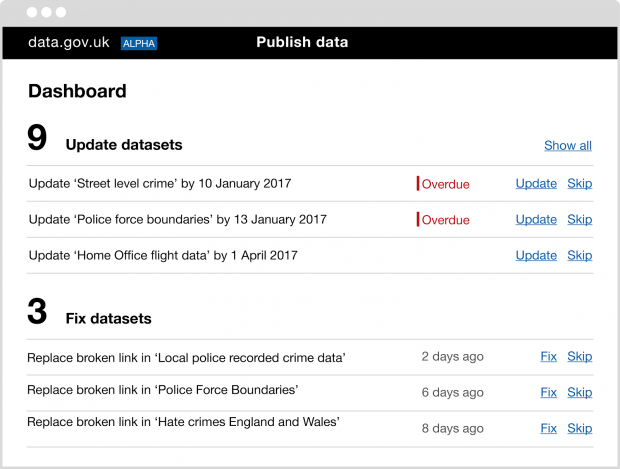
All of these improvements make it easier for users to find the information they need.
We’re also currently looking at how we could automate some of the publishing processes to support our publishers, reducing their responsibilities and increasing both the timeliness and quality of data.
What’s next
We’ll keep working with open data publishers in departments to get feedback on what we’ve built and we’ll keep iterating. We’re keen for more departments and agencies to test out the new service. If you’re interested in working with us, let us know, we’d like to speak to you.
1 comment
Comment by Peter Parslow posted on
As one of the publishers of government open data, we're very interested in this.
I'm sure you've noticed that more than half the entries on data.gov.uk identify themselves as 'location' - and that these have their own specific, standards based, way of getting published.
Although only a few dozen of those records originate from OS, I do have quite a handle on the standards & mechanisms used to make it work - both from the perspective of the Statutory Instruments that effectively specify it; the current (Defra-led) governance of those specs at European & UK level; through the metadata model, guidelines, and XML formats; and the API interactions that were implemented as CKAN extensions to enable to records to be harvested, and then passed on to an EU portal.
We involved The National Archives in that work (which preceded the existence of GDS), and there was some talk of adopting the metadata & harvesting approach for other 'non location' datasets (& service / APIs).
I thoroughly agree with the point on an earlier blog that metadata needs to be simple, but I would be very interested in being involved in any discussion of the future of the data.gov.uk publishing mechanism.