What’s address matching and why do we need it?
Departments, agencies and other service providers will often request and maintain their own address information. However, each organisation will capture slightly different information about an address or may store it in a particular format to suit their needs.
This means that address data is often inconsistent, is of varying quality, and can be held in multiple places. For example, Saltburn-by-the-sea can be written in many different ways including “Saltburn”, “Saltburn-by-sea”(with or without hyphens) and is often attributed to different counties.
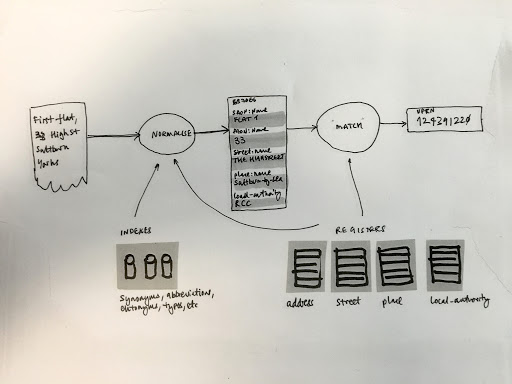
Matching addresses is much easier if they’re written in the same way, so we need a process where lots of existing data can be matched against something definitive and trustworthy. That’s where address matching comes in.
Matching addresses is tricky. It’s conducted across government for a range of reasons, such as processing addresses found as text in existing data and documents or exchanged between systems as a part of the process of using GOV.UK Verify.
Transforming government’s use of address data together
Since so many government services and operations use addresses, this isn’t something for us to tackle in isolation.
We’ve been working with colleagues from other departments and recently held a small workshop to share insights, highlight challenges and coordinate our efforts. We were joined by teams from the Office of National Statistics (ONS), HM Revenue and Customs, Valuation Office Agency, Ministry of Justice, and the Health and Safety Executive (HSE).
We kicked the day off with a show-and-tell of what each team was working on and why address matching is so important. It was fascinating to see the progress the HSE has made with their matching algorithm and learn about the extraordinary challenge the ONS are tackling in refining high-quality address information to support the 2021 national census.
The afternoon borrowed from the lean coffee method to give teams an opportunity to discuss the issues most pressing to them. We covered everything from the ways of validating an address match to the more philosophical point of what we mean when we talk about an ‘address’.
What we learnt
This takes us back to the address matching workshop.
First of all, we learnt that we’re all trying to achieve the same thing and we’re looking to go about it in a similar way. It’s much easier to match messy addresses to those that have already been cleansed and corrected. This means that part of our efforts need to be directed towards developing an authoritative set of address data.
As it currently stands, there’s a lot of manual verification involved in address matching and human beings find it much easier to spot errors in words (such as street and place names) than they do in numbers (such as postcodes). Not only will authoritative address data make this manual verification easier, but the workshop also highlighted that it will help the development of better automated processes to reduce the need for intensive manual effort.
We also realised that we need feedback loops to tidy up address data as efficiently as possible. This means that end users providing or searching for an address within a service can correct errors at the point of entry which can then be fed back into an address database. With approximately 30 million addresses in the UK, this means the quality of address data will improve the more it is used.
Finally, we discovered that additional information can actually make addresses less specific and even more difficult to match. For instance, streets in villages are often also attributed to a nearby town to avoid having a blank “town” line in address, such as “Staithes” being sometimes attributed to “Saltburn”, even though it’s 9 miles away and falls within a different local authority. Matching an address such as “High Street, Staithes, Saltburn” can be harder than the equally unique “High Street, Staithes” because there technically isn’t any such place. In addition to this, the more information requested or maintained, the more opportunity there is to introduce error.
Next steps
We’ve already started working on a shared vocabulary. ‘Address’ can mean slightly different things in different domains so it’s important to know whether we’re talking about a building, a Unique Property Reference Number (UPRN), a boundary, or the four lines and a postcode. We now have a collection of address terms that we’ll continue to iterate until we have agreed terminology across the group.
If we’re to crack address matching, we agreed that we’re going to need a comprehensive suite of test cases that exemplify some of the more difficult addresses to match. But this requires a high level of manual effort so we’ve created a public GitHub repository where each team can store and share these examples. It cuts down on the time and energy required and means that if one of the teams is able to successfully match one of the test cases, we can all learn from the approach.
There’s still a lot of work to be done and we’re already thinking about what we can cover in a follow-up session. The address matching workshop helped establish a community within the field and now all participants have a great forum for sharing problems and coming up with solutions together. If you’re working in government and you’d like to get involved in the community then just send me an email.
15 comments
Comment by Jessica Jenkins posted on
One thing I'd like to add to the discussion is alternative addresses for different languages. In Wales most addresses have alternative versions in Welsh and English. Both are correct, however one user today way want a completely different address than the next user tomorrow. For example, the fictional address Flat 1, Red House, New Road, Neath, SA10 9XX is exactly the same property as Fflat 1, Ty Coch, Heol Newydd, Castell Nedd, SA10 9XX. Any system must be able to cater for alternatives that seem nothing like the other.
Also don't make the assumption that only users of a Welsh interface language will want to use the Welsh address. The person using the service may be doing so in English on behalf of someone else who requires their address in Welsh. Or vice versa.
Comment by Rich Vale posted on
Hi Jessica,
Thanks for your comment. We have been doing some thinking around this. We think having a unique identifier for every address which brings together the different language ‘versions’ of that address provides the ability to control which ‘version’ is present to a user. We realise that there are lots of different ways people want to write and present their addresses so we should factor in the ability to choose the language you see something in.
Rich
Comment by Stuart Harrison posted on
When I was working on the (now hibernated) Open Addresses project, we built a web app that attempted to solve this problem at http://sorting-office.openaddressesuk.org/. It's far from perfect, but might be worth a look. The code's in Github (https://github.com/OpenAddressesUK/sorting_office), but give me a shout if you want more background on how it works.
Comment by Rich Vale posted on
Hi Stuart,
Thanks for this. In the course of our work we had helpfully been pointed towards the algorithm you’ve shared and we’ve been collecting a number of different algorithms that exist, such as LibPostal (https://github.com/openvenues/libpostal). We certainly recognise that a lot of work has been done in this field already which we can build upon. If we have any more questions as we delve deeper we’ll definitely give you a shout!
Rich
Comment by Richard Light posted on
Hi,
I assume that the ODI are part of this conversation. They have been looking at addresses as Linked Data for some time now, e.g. https://theodi.org/blog/open-addresses-and-linked-data.
Comment by Rich Vale posted on
Thanks Richard. We have been talking to the ODI and are aware of their work. We’re also working to make sure that everything we’re doing with registers is to be compatible with linked data.
Comment by Toby posted on
Of most importance, Address Data should be made open and free to use - a public good.
Comment by Frankie Roberto posted on
Re: "streets in villages are often also attributed to a nearby town to avoid having a blank “town” line in address, such as “Staithes” being sometimes attributed to “Saltburn”, even though it’s 9 miles away and falls within a different local authority"
"High Street, Staithes, Saltburn-by-the-Sea" is technically correct, at least as far as the Royal Mail / Post Office are concerned. The 'town' in addresses is the 'post town', and is present in every address, and doesn't refer to the address being within that town, or even belonging within the same local authority. Instead, historically they were the town where the delivery office for that address was located (which might be the office closest by travel time rather than distance).
Good luck with your project! Given there are numerous ways to write the same address, and even numerous notions of what 'an address' means, it's a complex problem!
Comment by Gayle Gander posted on
Addressing is an enormous issue and your blog highlights some of the issues around data sharing and maintenance. Back in 2010, GeoPlace was set up to create a new single source of address data (https://www.gov.uk/government/news/new-national-address-book-to-be-free-to-emergency-services). Taking data from local authorities, the statutory source of addressing, today we maintain just under 41 million addresses on a daily basis, providing a high quality authoritative set of address data – each record with its own UPRN. This takes away the need away for constant manual verification and effort. You might be interested to read former Cabinet Office Minister Matt Hancock’s presentation at the GeoPlace conference acknowledging the national Address Gazetteer as the single version of the truth and the UPRN as “the jewel at the heart of the addressing system” (https://www.gov.uk/government/speeches/geoplace-conference-matt-hancock-speech).
Comment by Ade Adewunmi posted on
Hi Gayle. Thanks for your comment - Richard is on leave at the moment but I really wanted to respond to your comment; hope I'll do :-). The blog post outlines the address matching that government departments need to do in the course of their day to day operations, and the things we're learning as we go. The similarities across this subset of bulk address data users present a brilliant opportunity to make sure we're sharing best matching techniques and continuously refining them. Once this matching is done, the next step, is to resolve it to an identifier - a process which is made immeasurably easier by having a canonical list of addresses. This is why the work that GeoPlace does is so important and something we fully recognise. That's what Rich was alluding to when he wrote "It’s much easier to match messy addresses to those that have already been cleansed and corrected".
Comment by Robert Whittaker posted on
Perhaps I'm missing something here, but surely in most cases, you just need to extract the postcode, and then check to see if the rest of the address is a fuzzy match for one of the canonical Royal Mail addresses listed for that postcode. If not, then you'll need a manual review. If it is, then you need to decide if you want to replace it with the canonical form, or if there's some additional information at the start (an un-registered sub-unit for example, such as a Department in a University or business) that needs to be kept.
Comment by Paul Downey posted on
Hi Robert, address data is collected for all sorts of purposes and in all sorts of ways. Consequently, not all addresses we need to match actually have a postcode attached (e.g. an incomplete address was provided), and in some cases the postcode provided by a user is incorrect (typos etc). So from an operational standpoint, we are always going to need to support "fuzzy matching" as well as translating the resulting text to an identifier for the place being addressed. This is what we mean by address matching. Government service providers often need to be able to do this to a very granular level for purposes as varied as licensing, valuation, etc.
Comment by Richard Murcott posted on
With one lens on the 'global village'? Do (will) the UK address efforts align with the international consensus on how to conceive addresses? Especially terminology. Ref. ISO 19160-1:2015 Addressing - Part 1: Conceptual model.
Comment by Paul Downey posted on
Completely agree with your point about the importance of, wherever possible, adopting/adhering to standards that are widely used e.g. BS7666.
Comment by Iain Goodwin posted on
Will your programme be looking at where there is opportunity to capture and cleanse addresses against UPRNs, to enable greater sharing and drive efficiencies across government?
I ask as I’m concerned that your programme is somewhat missing the point. If UPRNs were used and shared across the public sector you would have as close as you can to 100% match rates without need for any fuzzy matching.
Ambulance Trusts are a good example – they receive addresses from multiple sources which they are required to match to their AddressBase gazetteers, often in emergency situations. Confidence in match rates are key – receiving and matching addresses using UPRNs would give them that confidence. Sometimes if addresses can’t be matched emergency response is delayed.
This inefficiency is replicated across the public sector - there is a real need for one version of the truth for addresses. In my view capturing addresses against AddressBase and sharing UPRNs is the answer.